


很可惜 T 。T 您现在还不是作者身份,不能自主发稿哦~
如有投稿需求,请把文章发送到邮箱tougao@appcpx.com,一经录用会有专人和您联系
咨询如何成为春羽作者请联系:鸟哥笔记小羽毛(ngbjxym)
做一个对世界充满好奇的人!做数据分析就离不开相关“数据”的处理,而应用在数据分析中常见使用的两种主要语言是SQL和Python,还由于Excel处理十万以内的数据没有问题,但数据过多,处理效率就会下降,这时候就需要数据库SQL语句来处理了。SQL作为一种结构化查询语言,用于与关系数据库进行通信的标准语言,是数据分析人员离不开的工具。数据分析模型都来自关系数据库。
在数据分析招聘中,SQL也是必考能力之一,现在很多公司都有数据库,都需要学习SQL,可以说是基础技能了,现在是大数据时代,可能公司的数据非常之多,大数据是未来的趋势,在工作当中用sql还是比较多的。SQL主要体现数据查询、数据提取、数据监测上,如:
▶运营需要通过数据库追踪活动效果,通过数据反馈即使更改策略~
▶产品需要通过数据判断形式,通过数据调整方案~
·······
所以本期,数据·领地读书会的直播总结,就来跟大家一起来品读《SQL必知必会》,总结一下学习SQL的路径是怎么样的,这本书也没有过多阐述数据库基础理论,而是专门针对一线软件开发人员,直接从SQL SELECT开始,讲述实际工作环境中最常用和最必需的SQL知识,实用性极强。通过本书,读者能够从没有多少SQL经验的新手,迅速编写出世界级的SQL!
在这过程中,建议全程认真听,带着思考来听(去看),有任何问题都可以随时交流哦!
首先,说下为什么要学SQL,目前职场中不少的求职岗位都需要会sql的,尤其是数据分析相关岗位,是必备的能力之一,也是做数据分析利器,也是入门必学。
只要在工作中需要数据反馈的,都离不开SQL的使用。一般想通过SQL寻求岗位需要掌握以下几点就可以了
1)会利用SQL操作开关系数据库mysql进行查询
2)数据库的分组、聚合、排序
3)存储过程
4)对于增删改、约束、索引、数据库范式均大致了解即可,不需要深入
再来讲讲,学习SQL的路径是怎么样,回忆起来自己从刚开始不会SQL,到现在SQL 写的非常熟练,结合自己学习工作的经验,总结SQL学习路径,如下:
1)首先,先了解SQL 使用场景,数据库等相关概念。
只要跟数据相关的工作其实都可以用到SQL,特别是数据量较大的情况下,Excel 处理不了的情况下。
2)其次,学习SQL基本的语法,掌握一些简单的SQL书写。
包括select、where、group by、having、order by、delete、insert、join、update等,可以做日常的取数或简单的分析(该水平运营、产品等非数据岗就够了);
3)再学习掌握并熟练使用SQL高阶语法。
比如集合、分组聚合、子查询、条件逻辑、字符串函数、算术函数、日期时间函数,并且知道MySQL、Oracle、SQL Server等数据库的语法差异;
4)之后,进阶学习如何优化SQL语句,以期达到最高查询效率。
了解事务、锁、索引、约束、视图、元数据等概念,并且学会使用hive sql、spark sql、pymysql等工具,多表查询,窗口函数等~
5)最终,需要根据业务需求,将需求转化成SQL。
业务理解足够深,即知道需要用什么样的数据指标来分析、解决业务问题。比如说,统计一个班级的及格和不及格占比,统计考试中前20排名,
总之,SQL语言是数据分析工具之一,最终是为了服务于业务的。建⽴这个认知后以及基本的入门知识,之后你需要做的就是练习,练习,在练习。
《SQL必知必会》这本书的优点是可以快速入门,适合新手小白,语言通俗易懂,读着不会犯困。全书200来页,覆盖的知识点也很全:
·了解SQL(SQL基础概念)
·检索数据(Select语句)
·过滤数据(where 子句)
·创建计算字段(concat函数、||的用法)
·汇总数据(常见的聚合函数,如COUNT、MAX、SUM、AVG等)
·分组数据(Groupby、having)
·使用子查询(in & exits)
·表连接(left join 、right join 、full outer join)
·数据增删改(DDL、DML)
·使用视图
·使用存储过程
·使用游标
·····
那么,接下来,让我们来一起回顾一下:

什么是数据库,数据库就是存数据管理数据的一个东西系统,称之为数据库管理系统(Database Management System,DBMS),DBMS根据保存的格式分为5种,

层次数据库(Hierarchical Database,HDB)
关系数据库(Relational Database,RDB)
面向对象数据库(Object Oriented Database,OODB)
XML数据库(XML Database,XMLDB)
键值存储系统(Key-Value Store,KVS),举例:MongoDB
我们最常用的就是关系型数据库:
Oracle Database:甲骨文公司的RDBMS
SQL Server:微软公司的RDBMS
DB2:IBM公司的RDBMS
PostgreSQL:开源的RDBMS
MySQL:开源的RDBMS
数据库中存储的表结构类似于excel中的行和列,行称为记录,它相当于一条记录,列称为字段,主键:是这一列唯一标识表里的每一行,在这一列中没有重复的。
SQL是什么呢?SQL是跟数据库交流的语言,用SQL指挥数据库去干这个干那个,想让他干啥就干啥。
SQL的语言分三类,这个大概就了解一下,

第一类:DDL
DDL(Data Definition Language,数据定义语言) 用来创建或者删除存储数据用的数据库以及数据库中的表等对象。DDL 包含以下几种指令。
CREATE :创建数据库和表等对象
DROP :删除数据库和表等对象
ALTER :修改数据库和表等对象的结构
第二类:DML
DML(Data Manipulation Language,数据操纵语言) 用来查询或者变更表中的记录。变更:DML 包含以下几种指令。
SELECT :查询表中的数据
INSERT :向表中插入新数据
UPDATE :更新表中的数据
DELETE :删除表中的数据
第三类:DCL(了解)
DCL(Data Control Language,数据控制语言) 用来确认或者取消对数据库中的数据进行的变更。除此之外,还可以对 RDBMS 的用户是否有权限操作数据库中的对象(数据库表等)进行设定。DCL 包含以下几种指令。
COMMIT :确认对数据库中的数据进行的变更
ROLLBACK :取消对数据库中的数据进行的变更
GRANT :赋予用户操作权限
REVOKE :取消用户的操作权限
实际使用的 SQL 语句当中有 90% 属于 DML,已经认识数据库的基本信息了,那我们可以创建一个数据库。
#创建数据库-- 语法:CREATE DATABASE < 数据库名称 > ;CREATE DATABASE guagua;
创建好数据库之后还需要创建个表,数据是存储在表里,那就创建一个学生的表
#创建表/*语法:CREATE TABLE < 表名 >( < 列名 1> < 数据类型 > < 该列所需约束 > ,< 列名 2> < 数据类型 > < 该列所需约束 > ,< 列名 3> < 数据类型 > < 该列所需约束 > ,< 列名 4> < 数据类型 > < 该列所需约束 > ,...< 该表的约束 1> , < 该表的约束 2> ,……);*/CREATE TABLE students(sid int NOT NULL AUTO_INCREMENT,sname VARCHAR(100) NOT NULL,course VARCHAR(32) NOT NULL,score decimal(18,1) NOT NULL,sex varchar(10) ,class varchar(10) NOT NULL,Sage datetime,PRIMARY KEY(sid)) ;
这里可以稍微提一下命名规则:
书写规则:
数据库创建的表中都需要必须指定数据类型,如果创建错误会出现报错的情况。
四种最基本的数据类型
INTEGER 型:用来指定存储整数的列的数据类型(数字型),不能存储小数。
CHAR型用来存储定长字符串,当列中存储的字符串长度达不到最大长度的时候,使用半角空格进行补足,由于会浪费存储空间,所以一般不使用。
VARCHAR 型用来存储可变长度字符串,定长字符串在字符数未达到最大长度时会用半角空格补足,但可变长字符串不同,即使字符数未达到最大长度,也不会用半角空格补足。
DATE 型用来指定存储日期(年月日)的列的数据类型(日期型)。
指定数据类型之后后面还有一个not null,对存储的数据进行限制了,我们把这种叫做约束,约束分两种,一种是非空约束,就是必须输入数据,另一种是主键约束,代表唯一值,就是刚刚提到的。
AUTO_INCREMENT自增约束:每当增加一行时自动增量。每次执行一个INSERT操作时,MySQL自动对该列增量
DEFAULT:默认值设定
表的其他操作可以熟悉一下
# 修改表-- 添加列 ALTER TABLE < 表名 > ADD COLUMN < 列名 >;ALTER TABLE students ADD COLUMN aaa VARCHAR(100);-- 删除列 ALTER TABLE product DROP COLUMN aaa;ALTER TABLE students DROP COLUMN aaa ;# 删除表-- 整个表删除 DROP TABLE < 表名 > ;-- 删除的表是无法恢复的,只能重新插入,请执行删除操作时无比要谨慎-- 清空表TRUNCATE TABLE TABLE_NAME;-- 优点:相比drop``/``delete,truncate用来清除数据时,速度最快。# 注意:ALTER TABLE 语句和 DROP TABLE 语句一样,执行之后无法恢复
创建好数据库了然后可以把数据添加到数据库了,这样要用到insert into¥
# 插入数据-- INSERT INTO <表名> (列1, 列2, 列3, ……) VALUES (值1, 值2, 值3, ……);# 可以省略列名,会默认按照从左到右的顺序赋给每一列,不建议用insert into students (sname , course, score , sex , class , Sage ) values('赵雷' , '语文', 98 , '男', '一班','1990-12-21');insert into students (sname , course, score , sex , class , Sage ) values('赵雷' , '数学', 34 , '男', '一班','1990-12-21');insert into students (sname , course, score , sex , class , Sage ) values('赵雷' , '英语', 69 , '男', '一班','1990-12-21');insert into students (sname , course, score , sex , class , Sage ) values('李四' , '语文', 76 , '女', '二班','1991-12-21');insert into students (sname , course, score , sex , class , Sage ) values('李四' , '数学', 45 , '女', '二班','1991-12-21');insert into students (sname , course, score , sex , class , Sage ) values('李四' , '英语', 56 , '女', '二班','1991-12-21');insert into students (sname , course, score , sex , class , Sage ) values('李五' , '语文', 33 , '女', '三班','1994-12-21');insert into students (sname , course, score , sex , class , Sage ) values('李五' , '数学', 56 , '女', '三班','1994-12-21');insert into students (sname , course, score , sex , class , Sage ) values('李五' , '英语', 88 , '女', '三班','1994-12-21');#可以使用INSERT … SELECT 语句从其他表复制数据-- 将学生表的数据复制到学生表复制表中INSERT INTO students (sname , course, score , sex , class , Sage )SELECT sname , course, score , sex , class , SageFROM students;
执行一次 INSERT 语句会插入一行数据。插入多行时,通常需要循环执行 INSERT 语句,数据添加好了,想修改数据咋办,update...set...$
# 修改数据/*UPDATE <表名>SET <列名> = <表达式> [, <列名2>=<表达式2>...];WHERE <条件>; -- 可选,非常重要。*/-- 注意添加 where 条件,否则将会将所有的行按照语句修改,-- 把李五的性别改成女的,班级改成四班UPDATE studentsSET sex = '女', -- 可以讲null当做一个值来使用class = '四班'WHERE sname = '李五';-- UPDATE 语句的 SET 子句支持同时将多个列作为更新对象。
# 删除数据-- 删除数据跟修改数据语法相似,delect from <表名> where 条件 (非常重要)
删除数据跟修改数据相似就不在重复说了,重点就是不要忘记where。

1、简单查询
#从表中提取数据select * from students;select sname from students;select distinct sname from students;
值得一提的是如果
从表中选取数据:SELECT <列名>,<列名>,<列名> FROM <表名>;
注意:DISTINCT关键字作用于所有的列,不仅仅是跟在其后的那一列
想从中筛选出符合条件的列用where字句指定查询数的条件,where后面要跟条件表达式
算数运算符:四则运算
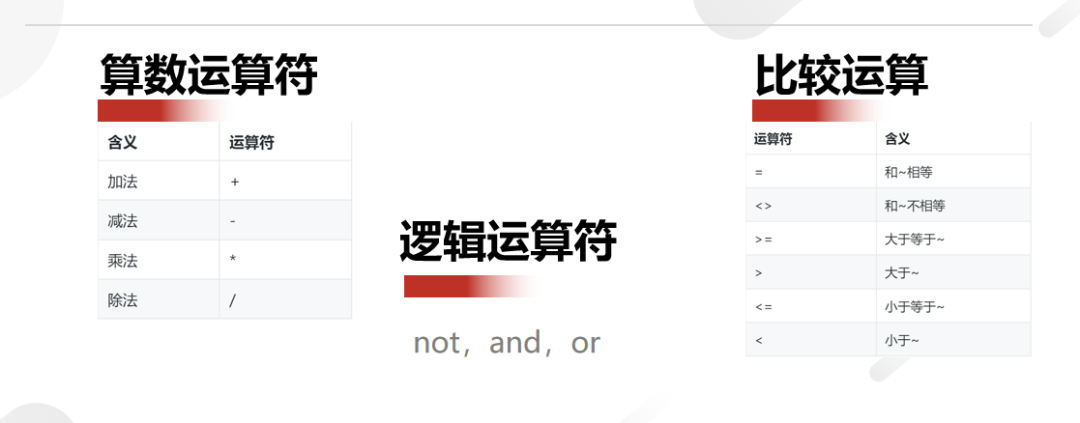
注意:如果有括号优先处理
还有 is null/is not null
#运用# 查询及格的信息select * from students where score>=60;#查询出一班和二班里及格的学生select * from students where score>=60 and (class='一班' or class='二班' ) ;-- 其他的方法自行探索
2、聚合查询
注意:聚合函数对null是排除在外的,COUNT(*)除外
COUNT(*)会得到包含NULL的数据行数,而COUNT(<列名>)会得到NULL之外的数据行数
# 计算最高分和最低分select max(score),min(score) from students;# 计算里面多少个学生select count(distinct sname) from students;
这些聚合函数运行的时候计算的整体的数,那我想分组汇总怎么办,那就可以用group by。
3、分组
group by
SELECT <列名1>,<列名2>, <列名3>, ……FROM <表名>GROUP BY <列名1>, <列名2>, <列名3>, ……;# 计算每个考试科目里面的最高分和最低分select course,max(score),min(score) from students group by course;
GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
group by 能不能使用别名,可以,where 不能使用别名
with rollup是用来在分组统计数据的基础上再进行统计汇总
having:过滤分组
分组统计之后想再添加条件过滤,那就用到having
# having 过滤分组# 语文和数学考试中最高分和最低分分别是多少select course,max(score),min(score) from students group by course having course in ('数学','语文') ;
where 和having非常类似,唯一的差别是WHERE过滤行,而HAVING过滤分组。HAVING支持所有WHERE操作符。
4、排序
order by:排序
SELECT <列名1>, <列名2>, <列名3>, ……FROM <表名>ORDER BY <排序基准列1>, <排序基准列2>, ……
SQL中的执行结果是随机排列的,当需要按照特定顺序排序时,可已使用ORDER BY子句。
order by中可以使用别名
ps:语句的执行顺序


1、函数
函数大致分为如下几类:
●算术函数 (用来进行数值计算的函数)
●字符串函数 (用来进行字符串操作的函数)
●日期函数 (用来进行日期操作的函数)
●转换函数 (用来转换数据类型和值的函数)
●聚合函数 (用来进行数据聚合的函数)
算术函数
●ABS – 绝对值
●MOD – 求余数,语法:MOD( 被除数,除数 )
●ROUND – 四舍五入,语法:ROUND( 对象数值,保留小数的位数 )
字符串函数
●CONCAT – 拼接,语法:CONCAT(str1, str2, str3)
●LENGTH – 字符串长度,语法:LENGTH( 字符串 )
●LOWER – 小写转换
●REPLACE – 字符串的替换,语法:REPLACE( 对象字符串,替换前的字符串,替换后的字符串 )
●LETF-从左开始截取字符串,语法:LEFT(被截取字段,截取长度)
●RIGHT-从右开始截取字符串,语法:right(被截取字段,截取长度)
●mid-自定义截取,语法:mid(被截取字段,从那位置开始,截取几个字符数)
●SUBSTRING – 截取字符串,substring(被截取字段,从第几位开始截取) ,substring(被截取字段,从第几位开始截取,截取长度)
●SUBSTRING_INDEX –按关键字截取字符串,语法:substring_index(被截取字段,分隔符,关键字出现的次数)
●group_concat,字符串分组拼接
# 字符串截取select substring_index('赵雷-一班-一年级',"-",1) ; -- 从左边关键字出现第1次,截取字符串之前所有select substring_index('赵雷-一班-一年级',"-",2) ; -- 从左边关键字出现第2次,截取字符串之前所有select substring_index('赵雷-一班-一年级',"-",-1) ; -- 从右边关键字出现第1次,截取字符串之前
日期函数
DATE(),返回日期。格式:YYYY-MM-DD
TIME(),返回日期。格式:HH-mm-ss
TIMESTAMP(),返回日期时间。格式:YYYY-MM-DD HH-mm-ss
NOW()、CURRENT_TIMESTAMP、CURRENT_TIMESTAMP(),返回语句开始执行的时间
SYSDATE() 返回的是这个函数执行时候的时间
select SLEEP(1),NOW(),CURRENT_TIMESTAMP,CURRENT_TIMESTAMP(),SYSDATE();DATE_FORMAT(),将日期根据指定的格式返回为对应的字符串
date_sub,时间减
date_add,时间加
select SLEEP(1),NOW(),CURRENT_TIMESTAMP,CURRENT_TIMESTAMP(),SYSDATE();SELECT DATE_FORMAT('2022-01-01 22:00:00','%Y-%m-%d');SELECT DATE_ADD('2022-01-01 22:00:00',interval 2 day);#往前加两天SELECT DATE_ADD('2022-01-01 22:00:00',interval -2 day);#往后加两天SELECT DATE_ADD('2022-01-01 22:00:00',interval 2 month);#往前加两月
其他函数
like函数,通配符
between,注意:左右两边是闭区间
is null,is not null
in和not in 支持子查询
case 表达式
通配符:用来匹配值的一部分的特殊字符,使用通配符就必须使用like
# %通配符:%表示任何字符出现任意次数# 匹配李开头的学员信息select * from students where sname like '李%'# _ 通配符,只匹配单个字符# 匹配李某select * from students where sname like '李_'
case表达式
#case when then语法CASE WHEN <求值表达式> THEN <表达式>WHEN <求值表达式> THEN <表达式>WHEN <求值表达式> THEN <表达式>...ELSE <表达式>END# 添加一列及格和不及格# case函数select *,(case when score >= 60 then '及格' else '不及格' end) from students;# 行转列,科目放在表头select sname,(case when course ='语文' then score else null end) as '语文',(case when course ='数学' then score else null end) as '数学',(case when course ='英语' then score else null end) as '英语'from students ;select sname,sum((case when course ='语文' then score else null end)) as '语文',sum((case when course ='数学' then score else null end)) as '数学',sum((case when course ='英语' then score else null end)) as '英语'from students group by sname ;
2、视图
什么是视图?虚拟表,视图是依据SELECT语句来创建的,所以说是select语句生产的虚拟表叫视图。
# 创建视图CREATE VIEW <视图名称>(<列名1>,<列名2>,...) ASCREATE view st (sname,score)asselect sname,score from students;
3、子查询
子查询指一个查询语句嵌套在另一个查询语句内部的查询
子查询的结果可以作为一个表,也可以作为一个过滤条件
# 作为一个表--嵌套子查询select 列名 from(select 列名 from 表1 where 列 where 表达式) as 子查询 -- 结果作为一个表# 作为一个结果-- 标量子查询select 列名 from 表1 where 列名 = (select max(列名) from 表1 )# 成绩高于平均值select * from students where score>= (select avg(score) from students )
还有一种是关联子查询,有关联两个字就意味着查询与子查询之间存在着联系,那么联系是如何建立起来的
# 各个科目中高于该科目的成绩select sname,course,score from students as a where score>=(select avg(score) as avg_score from students as bwhere a.course=b.course )

关键字:union ,union all,join,iinner join,outer join,left join,right join。
1、上下拼接
用UNION将多条SELECT语句组合成一个结果集
注意:UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔;
union 是去重,union all 是不去重的,只能使用一条ORDER BY子句,它必须出现在最后一条SELECT语句之后。列需要进行对齐操作。
# unionselect 123 as 数字 union select 456# 排序select 123 as 数字 union select 456 order by 数字 desc
2、联结
·内连接
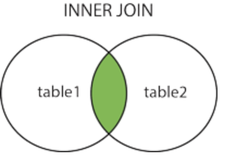
-- 内连结FROMINNER JOIN ON
INNER 关键词表示使用了内连结
注意:
必须使用 ON 子句来指定连结条件,在进行内连结时 ON 子句是必不可少的,ON 子句是专门用来指定连结条件的。
SELECT 子句中的列最好按照 表名.列名 的格式来使用。如果两张表有其他名称相同的列, 则必须使用上述格式来选择列名,,否则查询语句会报错。
如果需要在使用内连结的时候同时使用 WHERE 子句对检索结果进行筛选,则需要把 WHERE 子句写在 ON 子句的后边。
where的使用方法:
子查询,上述查询作为子查询, 用括号封装起来, 然后在外层查询增加筛选条件.
on后面加where,查询的执行顺序:FROM 子句->WHERE 子句->SELECT 子句,在做完 INNER JOIN … ON 得到一个新表后, 才会执行 WHERE 子句
select 列 from 表1 inner join 表2 on 列1=列2 where 列条件select 列 from (select 列 from 表1 inner join 表2 on 列1 = 列2) as 表3where 列条件
·自然联结NATURAL JOIN
会按照两个表中都包含的列名来进行等值内连结,此时无需使用 ON 来指定连接条件。使用自然连结还可以求出两张表或子查询的公共部分。
SELECT * FROM 表1 NATURAL JOIN 表2·外连接
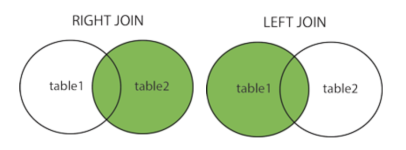
LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
左右联结最终要的一个点是选要把哪张表作为主表,使用 LEFT 时 FROM 子句中写在左侧的表是主表,使用 RIGHT 时右侧的表是主表。
-- 左连结FROMLEFT JOIN ON -- 右连结FROMRIGHT JOIN ON -- 全外连结,mysql不支持全外联结FROMFULL JOIN ON -- 交叉连结,CROSS JOIN(笛卡尔积)FROMCROSS JOIN
什么是笛卡尔积: 就是使用集合 A 中的每一个元素与集合 B 中的每一个元素组成一个有序的组合。
没有了ON子句的限制,会对左表和右表的每一行进行组合。

窗口函数称之为OLAP,对数据进行实时分析处理,常规的SELECT语句都是对整张表进行查询,而窗口函数可以让我们有选择的去某一部分数据进行汇总、计算和排序。
窗口函数的通用公式:
<窗口函数> OVER ([PARTITION BY <列名>] ORDER BY <排序用列名>)
红色的地方可以省略,最关键的是PARTITON BY,PARTITON英文是分割的意思,可以理解为PARTITON BY是用来分组,这个分组的意思是表中哪些行是一组。
order by是用来排序的,决定在窗口内,哪些规则是来排序的
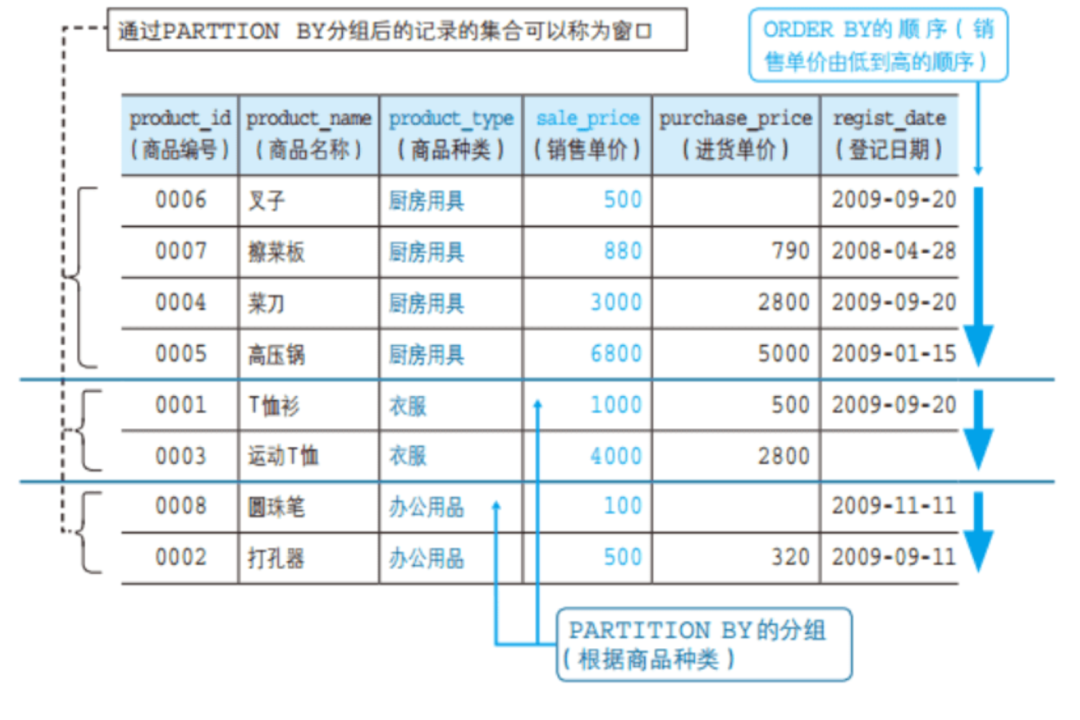
1、排序类的窗口函数
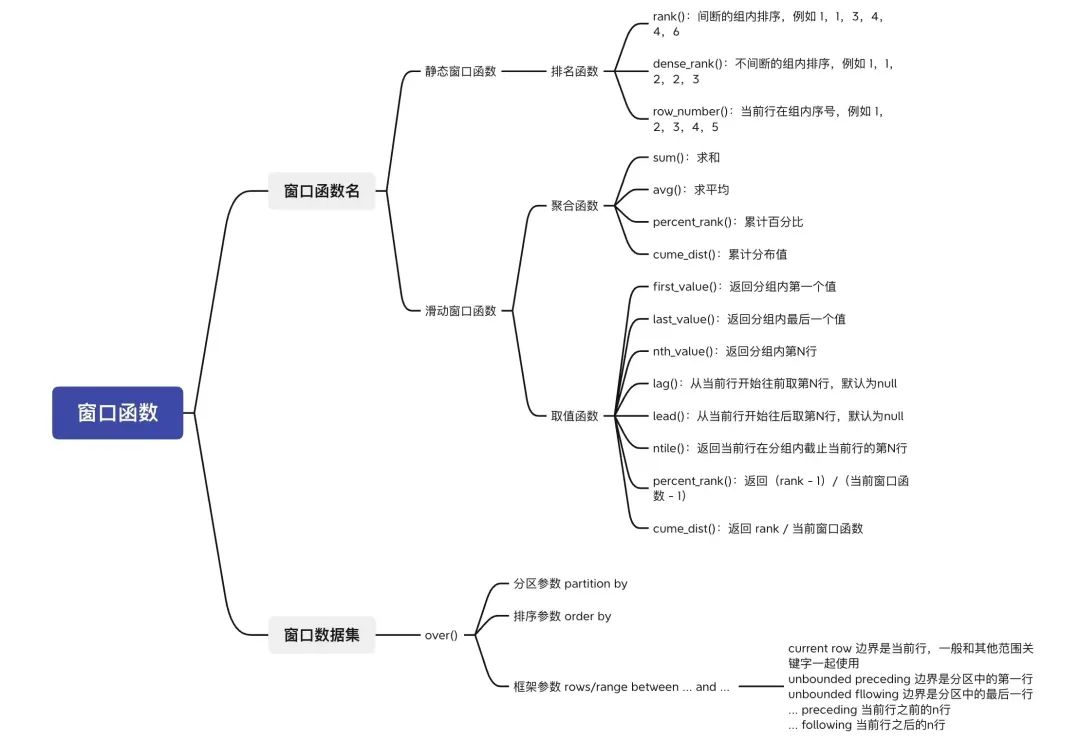
RANK函数:如果存在相同位次的记录,则会跳过之后的位次,1134...
DENSE_RANK函数:即使存在相同位次的记录,也不会跳过之后的位次。11234
ROW_NUMBER函数:连续位次,依次排序不会重复,1233
# 英语成绩排名
select sname,course,score,rank() over (order by score desc) as ranking,dense_rank() over (order by score desc) as dense_ranking,row_number() over (order by score desc) as row_numfrom students where course='英语';# 根据科目进行排序select sname,course,score,rank() over (PARTITION BY course order by score desc) as ranking,dense_rank() over (PARTITION BY course order by score desc ) as dense_ranking,row_number() over (PARTITION BY course order by score desc) as row_numfrom students
2、聚合函数使用
出来的结果是一个累计的聚合函数值,根据分组情况进行累计计算,比如求和,平均,最大,最小,计数
sum,累计求和
avg,移动平均
count
max
min
elect sname,course,score,sum(score) over ( order by score ) as current_sum,avg(score) over ( order by score ) as current_avg,count(*) over ( order by score desc ) as count_,max(score) over ( order by score desc ) as max_score,min(score) over ( order by score ) as min_scorefrom students# 分组排序select sname,course,score,sum(score) over ( PARTITION BY course order by score desc ) as current_sum,avg(score) over ( PARTITION BY course order by course ) as current_avg,count(*) over ( PARTITION BY course order by score desc) as count_,max(score) over ( PARTITION BY course order by score desc ) as max_score,min(score) over (PARTITION BY course order by course ) as min_scorefrom students
3、移动平均
<窗口函数> OVER (ORDER BY <排序用列名>ROWS n PRECEDING )<窗口函数> OVER (ORDER BY <排序用列名>ROWS BETWEEN n PRECEDING AND n FOLLOWING)
PRECEDING(“之前”), 将框架指定为 “截止到之前 n 行”,加上自身行FOLLOWING(“之后”), 将框架指定为 “截止到之后 n 行”,加上自身行BETWEEN 1 PRECEDING AND 1 FOLLOWING,将框架指定为 “之前1行” + “之后1行” + “自身”
# 移动平均select sname,course,score,AVG(score) OVER (ORDER BY courseROWS 2 PRECEDING) AS moving_avg -- 之前2行,AVG(score) OVER (ORDER BY courseROWS BETWEEN 1 PRECEDINGAND 1 FOLLOWING) AS moving_avg -- 前一行,后一行from students
以上就是本次分享的全部内容!《SQL必知必会》一本非常经典的数据库书籍,也可以说是自己入门数据库的书。本次分享也是精华整理,本书的讲解主要是通过5个不同表来完成,结合各种案例来说明SQL的使用细节。
那么,数据分析人员到底应该掌握到SQL到什么程度呢?
其实不同数据分析岗位对于SQL掌握程度的要求和标准是不同。如偏业务分析的数据岗数据分析师/商业分析师,对SQL的掌握也会有一定要求,不过也不必说一定要十分精通,只要可以从数据仓库里取数、学会一些常见的SQL语句就行,取数并不是业务分析师的主要工作,而且很多人用现成的BI工具,或者是直接Python,虽然也会需要SQL从数据库中取数,但是不用去考虑复杂的逻辑。
如果说是做数据分析工程师等偏技术的数据岗,必须要去精通SQL了,如复杂综合查询、窗口函数、多表查询等都是需要掌握的,而且更好地提高检索速度对于业务方面来说比较重要。
当然在面试中,于转行数据分析岗位,对于SQL是必须的,于产品、运营、财务等非数据岗位,学会了是加分项。当然,还是那句话,有些东西你用了才知道它有用,不用它永远没用,所以学习知识是比较容易,但是把知识应用到实际的工作和生活中是比较难的事,需要我们去实践,去思考、去练习。
最后,祝愿大家都能在自己所在的领域内,保持着好奇心、求知欲、观察生活,在实际场景中,要有数据驱动产品闭环的思维,熟悉业务,时刻关注数据、保持敏感,成就更好的自己,在可预见的未来,遇到更好的自己。
后期内容我们还有继续为大家分享很多的关于数据分析案例以及的数据书籍内容:数据分析项目分享、商业案例分享、高阶书籍分享···
本次分享到此结束,感谢大家的收听,我们下期再会!
本文为作者独立观点,不代表鸟哥笔记立场,未经允许不得转载。
《鸟哥笔记版权及免责申明》 如对文章、图片、字体等版权有疑问,请点击 反馈举报



















Powered by QINGMOB PTE. LTD. © 2010-2025 上海青墨信息科技有限公司 沪ICP备2021034055号-6



























我们致力于提供一个高质量内容的交流平台。为落实国家互联网信息办公室“依法管网、依法办网、依法上网”的要求,为完善跟帖评论自律管理,为了保护用户创造的内容、维护开放、真实、专业的平台氛围,我们团队将依据本公约中的条款对注册用户和发布在本平台的内容进行管理。平台鼓励用户创作、发布优质内容,同时也将采取必要措施管理违法、侵权或有其他不良影响的网络信息。
一、根据《网络信息内容生态治理规定》《中华人民共和国未成年人保护法》等法律法规,对以下违法、不良信息或存在危害的行为进行处理。
1. 违反法律法规的信息,主要表现为:
1)反对宪法所确定的基本原则;
2)危害国家安全,泄露国家秘密,颠覆国家政权,破坏国家统一,损害国家荣誉和利益;
3)侮辱、滥用英烈形象,歪曲、丑化、亵渎、否定英雄烈士事迹和精神,以侮辱、诽谤或者其他方式侵害英雄烈士的姓名、肖像、名誉、荣誉;
4)宣扬恐怖主义、极端主义或者煽动实施恐怖活动、极端主义活动;
5)煽动民族仇恨、民族歧视,破坏民族团结;
6)破坏国家宗教政策,宣扬邪教和封建迷信;
7)散布谣言,扰乱社会秩序,破坏社会稳定;
8)宣扬淫秽、色情、赌博、暴力、凶杀、恐怖或者教唆犯罪;
9)煽动非法集会、结社、游行、示威、聚众扰乱社会秩序;
10)侮辱或者诽谤他人,侵害他人名誉、隐私和其他合法权益;
11)通过网络以文字、图片、音视频等形式,对未成年人实施侮辱、诽谤、威胁或者恶意损害未成年人形象进行网络欺凌的;
12)危害未成年人身心健康的;
13)含有法律、行政法规禁止的其他内容;
2. 不友善:不尊重用户及其所贡献内容的信息或行为。主要表现为:
1)轻蔑:贬低、轻视他人及其劳动成果;
2)诽谤:捏造、散布虚假事实,损害他人名誉;
3)嘲讽:以比喻、夸张、侮辱性的手法对他人或其行为进行揭露或描述,以此来激怒他人;
4)挑衅:以不友好的方式激怒他人,意图使对方对自己的言论作出回应,蓄意制造事端;
5)羞辱:贬低他人的能力、行为、生理或身份特征,让对方难堪;
6)谩骂:以不文明的语言对他人进行负面评价;
7)歧视:煽动人群歧视、地域歧视等,针对他人的民族、种族、宗教、性取向、性别、年龄、地域、生理特征等身份或者归类的攻击;
8)威胁:许诺以不良的后果来迫使他人服从自己的意志;
3. 发布垃圾广告信息:以推广曝光为目的,发布影响用户体验、扰乱本网站秩序的内容,或进行相关行为。主要表现为:
1)多次发布包含售卖产品、提供服务、宣传推广内容的垃圾广告。包括但不限于以下几种形式:
2)单个帐号多次发布包含垃圾广告的内容;
3)多个广告帐号互相配合发布、传播包含垃圾广告的内容;
4)多次发布包含欺骗性外链的内容,如未注明的淘宝客链接、跳转网站等,诱骗用户点击链接
5)发布大量包含推广链接、产品、品牌等内容获取搜索引擎中的不正当曝光;
6)购买或出售帐号之间虚假地互动,发布干扰网站秩序的推广内容及相关交易。
7)发布包含欺骗性的恶意营销内容,如通过伪造经历、冒充他人等方式进行恶意营销;
8)使用特殊符号、图片等方式规避垃圾广告内容审核的广告内容。
4. 色情低俗信息,主要表现为:
1)包含自己或他人性经验的细节描述或露骨的感受描述;
2)涉及色情段子、两性笑话的低俗内容;
3)配图、头图中包含庸俗或挑逗性图片的内容;
4)带有性暗示、性挑逗等易使人产生性联想;
5)展现血腥、惊悚、残忍等致人身心不适;
6)炒作绯闻、丑闻、劣迹等;
7)宣扬低俗、庸俗、媚俗内容。
5. 不实信息,主要表现为:
1)可能存在事实性错误或者造谣等内容;
2)存在事实夸大、伪造虚假经历等误导他人的内容;
3)伪造身份、冒充他人,通过头像、用户名等个人信息暗示自己具有特定身份,或与特定机构或个人存在关联。
6. 传播封建迷信,主要表现为:
1)找人算命、测字、占卜、解梦、化解厄运、使用迷信方式治病;
2)求推荐算命看相大师;
3)针对具体风水等问题进行求助或咨询;
4)问自己或他人的八字、六爻、星盘、手相、面相、五行缺失,包括通过占卜方法问婚姻、前程、运势,东西宠物丢了能不能找回、取名改名等;
7. 文章标题党,主要表现为:
1)以各种夸张、猎奇、不合常理的表现手法等行为来诱导用户;
2)内容与标题之间存在严重不实或者原意扭曲;
3)使用夸张标题,内容与标题严重不符的。
8.「饭圈」乱象行为,主要表现为:
1)诱导未成年人应援集资、高额消费、投票打榜
2)粉丝互撕谩骂、拉踩引战、造谣攻击、人肉搜索、侵犯隐私
3)鼓动「饭圈」粉丝攀比炫富、奢靡享乐等行为
4)以号召粉丝、雇用网络水军、「养号」形式刷量控评等行为
5)通过「蹭热点」、制造话题等形式干扰舆论,影响传播秩序
9. 其他危害行为或内容,主要表现为:
1)可能引发未成年人模仿不安全行为和违反社会公德行为、诱导未成年人不良嗜好影响未成年人身心健康的;
2)不当评述自然灾害、重大事故等灾难的;
3)美化、粉饰侵略战争行为的;
4)法律、行政法规禁止,或可能对网络生态造成不良影响的其他内容。
二、违规处罚
本网站通过主动发现和接受用户举报两种方式收集违规行为信息。所有有意的降低内容质量、伤害平台氛围及欺凌未成年人或危害未成年人身心健康的行为都是不能容忍的。
当一个用户发布违规内容时,本网站将依据相关用户违规情节严重程度,对帐号进行禁言 1 天、7 天、15 天直至永久禁言或封停账号的处罚。当涉及欺凌未成年人、危害未成年人身心健康、通过作弊手段注册、使用帐号,或者滥用多个帐号发布违规内容时,本网站将加重处罚。
三、申诉
随着平台管理经验的不断丰富,本网站出于维护本网站氛围和秩序的目的,将不断完善本公约。
如果本网站用户对本网站基于本公约规定做出的处理有异议,可以通过「建议反馈」功能向本网站进行反馈。
(规则的最终解释权归属本网站所有)